


Pourquoi les réponses d’une intelligence artificielle semblent-elles parfois si humaines alors qu’elle ne ressent rien ? Comprendre comment fonctionne un modèle LLM permet de lever le voile sur ce traitement statistique où la donnée textuelle se transforme en vecteurs mathématiques au sein d’une architecture Transformer. Ce briefing technique vous révèle les mécanismes de l’auto-attention et du pré-entraînement massif qui permettent à ces réseaux de neurones de prédire le langage avec une précision chirurgicale.
- Les bases du fonctionnement d’un modèle LLM par la donnée
- L’architecture Transformer au cœur de la prédiction
- Du pré-entraînement à l’alignement humain
- Mécanismes de génération et stratégies de décodage
- Lois d’échelle et développement de capacités imprévues
- Solutions techniques face aux limites de mémorisation
Les bases du fonctionnement d’un modèle LLM par la donnée
Après avoir posé le décor sur l’importance de l’IA, nous allons voir comment ces machines transforment nos mots en purs chiffres.
Tokenisation : segmenter le langage en unités mathématiques
Le texte brut est systématiquement découpé en morceaux élémentaires nommés tokens. Cette unité ne correspond pas toujours à un mot entier. Elle représente souvent des syllabes ou des groupes de caractères.
Chaque segment reçoit ensuite un identifiant numérique unique dans le répertoire du modèle. Cette conversion permet à l’ordinateur de manipuler le langage via des calculs. Les chiffres remplacent alors définitivement les lettres pour la machine.
Plus petite unité de texte (syllabe ou mot) traitée par le modèle pour standardiser la donnée.
Cette méthode facilite grandement la gestion de plusieurs langues simultanément. Le modèle traite des motifs statistiques universels. Il s’affranchit ainsi des règles grammaticales trop rigides.
Espace sémantique et regroupement des concepts par vecteurs
Les embeddings fonctionnent comme des points précis positionnés dans un espace mathématique immense. Chaque mot possède des coordonnées spécifiques. On peut y voir une véritable carte géographique du sens.
Le système regroupe naturellement les concepts dont le sens est proche. Par exemple, chat et chien se situent dans la même zone. La proximité physique indique une parenté logique forte.
Il devient alors possible de comprendre comment utiliser l’intelligence artificielle au quotidien pour traiter des volumes massifs de données textuelles complexes.
Coordonnées mathématiques représentant le sens d’un mot dans un espace à plusieurs dimensions.
Le modèle capture aussi des relations logiques sophistiquées. Il saisit que roi est à homme ce que reine est à femme.
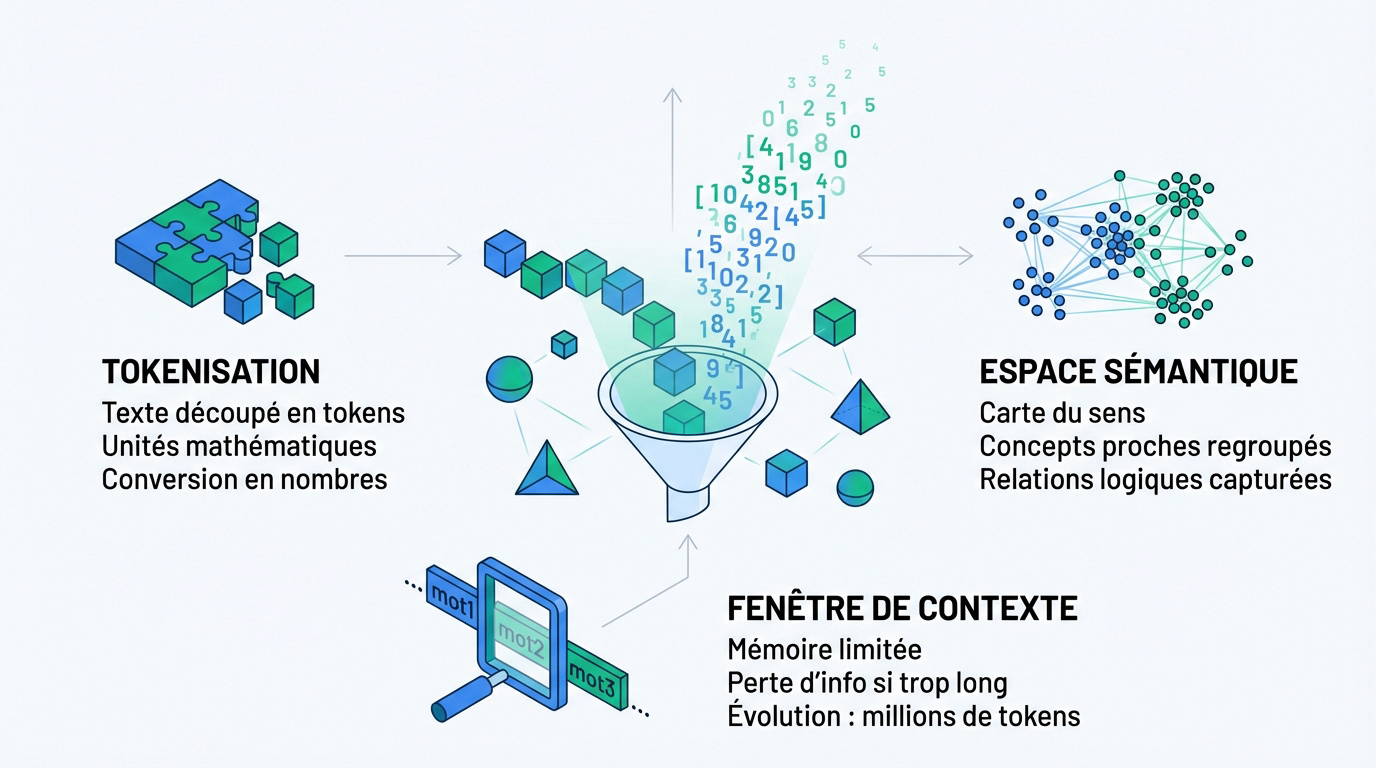
Impact de la fenêtre de contexte sur la mémoire immédiate
La fenêtre de contexte limite le nombre de jetons traitables simultanément par l’algorithme. Elle définit strictement sa mémoire courte. C’est la capacité de rétention lors d’une session unique.
Une perte d’information survient inévitablement lorsque le texte dépasse ce seuil. Le modèle finit par oublier le début de l’échange. Les détails techniques s’évaporent au-delà de sa capacité maximale.
Les ingénieurs travaillent activement à l’extension de cette limite physique. Certaines architectures supportent désormais des millions de tokens. Les capacités de traitement progressent de manière exponentielle.
Cette contrainte technique reste fondamentale aujourd’hui. Elle conditionne directement la cohérence globale des longs documents générés.
L’architecture Transformer au cœur de la prédiction
Une fois les mots numérisés, il faut une structure capable de les organiser intelligemment, et c’est là qu’intervient le Transformer.
Mécanisme d’attention : le trio Query, Key et Value
Le système de pondération permet au modèle d’analyser chaque mot par rapport aux autres. Il détermine précisément l’importance de chaque élément au sein de la séquence. Cette hiérarchisation assure une compréhension fine.
Les vecteurs Query, Key et Value fonctionnent comme une recherche dans un catalogue. Le modèle identifie la meilleure correspondance entre ces vecteurs. Cela permet de donner un sens global et cohérent à la phrase entière.
Query : Ce que le modèle recherche.
Key : L’étiquette de chaque mot en base.
Value : Le contenu informationnel réellement extrait.
Ce processus ressemble à l’interrogation d’une base de données. L’attention se focalise sur l’essentiel. Elle permet d’ignorer les bruits inutiles du texte.
Différences entre modèles autorégressifs et approches masquées
La prédiction mot à mot s’oppose à la reconstruction globale. Certains modèles devinent la suite d’une séquence. D’autres remplissent des trous laissés dans une phrase incomplète.
La génération fluide privilégie l’approche autorégressive pour sa continuité. En revanche, la compréhension profonde utilise souvent des modèles masqués. BERT est l’exemple type de cette méthode bidirectionnelle.
L’évolution technologique mène vers une IA 2026 | Modèles multimodaux et agents autonomes – Guide de plus en plus intégrée. Ces systèmes hybrides redéfinissent les capacités actuelles.
L’efficacité varie selon l’objectif final de l’outil. Le choix technique dépend de la tâche demandée.
Empilement des couches pour une abstraction croissante
Les données circulent à travers des dizaines de couches de neurones. Chaque étape affine progressivement la compréhension globale. Les informations brutes se transforment en représentations structurées.
Les couches profondes saisissent le sens le plus complexe. Au départ, le modèle identifie de simples lettres. À la fin, il perçoit l’ironie ou un style spécifique.
La structure multi-têtes analyse plusieurs relations simultanément. Cela offre une vision parallèle et riche du texte. Le modèle traite ainsi diverses nuances grammaticales en même temps.
L’empilement crée une puissance d’analyse remarquable. Plus les couches sont nombreuses, plus le modèle devient subtil.

Du pré-entraînement à l’alignement humain
L’architecture est prête, mais elle est vide ; il faut maintenant la gaver de données pour qu’elle apprenne à parler.
Apprentissage auto-supervisé sur des volumes massifs de texte
Le modèle commence par une exposition initiale au web. Il lit des milliards de pages pour s’imprégner du langage. Il absorbe tout ce qui traîne sur internet et dans les livres.
Cette phase permet l’acquisition passive de la grammaire. Sans professeur, l’IA devine comment les phrases se construisent. Elle stocke des connaissances générales sur le monde entier de manière statistique.
Cependant, le coût énergétique est colossal. Cette phase demande des milliers de puces graphiques performantes. C’est un investissement matériel et financier massif.
- Pré-entraînement : Absorption massive de données web non étiquetées.
- Fine-tuning : Apprentissage spécifique pour suivre des instructions.
- RLHF : Alignement par retour humain pour la sécurité.
Fine-tuning pour l’ajustement aux instructions spécifiques
L’entraînement devient alors spécialisé sur des données de haute qualité. On utilise des exemples de dialogues parfaits. Le modèle apprend à devenir un bon interlocuteur pour l’utilisateur.
L’IA apprend progressivement à obéir aux requêtes. Elle comprend enfin ce qu’est une consigne précise. Répondre à une question devient sa priorité absolue dans ce cadre.
Cette étape favorise l’automatisation par intelligence artificielle et son essor dans les entreprises. Le modèle s’adapte à des domaines précis.
Le prédicteur statistique devient alors un outil utile. Il se transforme en véritable assistant.
Rôle du RLHF dans la sécurité et la pertinence
Le processus intègre l’apprentissage par renforcement humain. Des gens notent les réponses générées par le modèle. Ils indiquent quelle version est la plus polie ou exacte.
Ce mécanisme permet le filtrage des contenus toxiques. Le RLHF apprend au modèle à éviter les insultes. Il bride les comportements dangereux ou inappropriés pour le public.
L’alignement est indispensable pour l’utilisabilité globale. Sans lui, l’IA serait imprévisible. Elle pourrait raconter n’importe quoi sans aucun filtre moral ou factuel.
C’est l’étape qui rend l’IA acceptable pour le public. La sécurité est ainsi mieux garantie.
Mécanismes de génération et stratégies de décodage
Savoir est une chose, mais produire une réponse cohérente en temps réel demande une stratégie de calcul bien précise.
Calcul des probabilités pour la prédiction du prochain jeton
Le processus repose sur une sélection statistique rigoureuse du mot suivant. Le modèle calcule quel jeton est le plus probable selon le contexte. Il ne réfléchit pas, il parie.
Cette architecture démontre une absence totale de conscience propre. L’IA n’a pas d’idées, elle traite seulement des fréquences de mots. Chaque phrase résulte d’un tirage mathématique complexe et automatisé.
Le texte produit est par nature probabiliste. Une sollicitation identique peut générer deux réponses distinctes. C’est le principe du hasard dirigé.
Paramètres de température et échantillonnage Top-K
La température influence directement la distribution des probabilités. Une valeur haute favorise l’originalité et la surprise. À l’inverse, une valeur basse rend le contenu très prévisible.

Le filtrage Top-K limite les choix aux segments les plus crédibles. On élimine les termes les moins probables dès le début. Cela évite au modèle de formuler des propositions absurdes.
Utilisez une température basse (0.1-0.3) pour les faits et le code. Préférez une valeur haute (0.7-1.0) pour la création.
Certains utilisateurs explorent les meilleurs outils ia 2026 pour votre productivité afin d’ajuster ces réglages. Ces paramètres varient selon l’objectif visé.
On adapte les réglages à la tâche. La rigueur est requise pour le code informatique.
Distinction entre simulation de raisonnement et calcul statistique
Il faut clarifier l’absence de compréhension réelle du système. L’IA imite l’humain sans ressentir les concepts manipulés. Elle agit comme un miroir de nos propres données textuelles.
Cette approche explique les erreurs logiques parfois observées. Le modèle peut se tromper sur des calculs arithmétiques simples. Il privilégie la probabilité statistique plutôt que la vérité factuelle.
La différence avec la déduction humaine est fondamentale. L’IA pioche dans une mémoire statistique massive. Elle ne crée jamais de nouveaux concepts logiques par elle-même.
L’utilisateur doit garder en tête la nature de l’outil. C’est un moteur de prédiction, rien de plus.
Lois d’échelle et développement de capacités imprévues
En faisant grossir ces modèles, les chercheurs ont découvert des talents qu’ils n’avaient jamais programmés au départ.
Scaling laws : l’influence du volume de paramètres
La performance d’un système dépend directement de son envergure technique. Plus le modèle gagne en volume, plus sa finesse d’analyse s’accroît. Cette progression suit une trajectoire mathématique remarquablement prévisible.
L’industrie assiste à une inflation massive du nombre de neurones artificiels. Les architectures intègrent des milliards de paramètres pour traiter des corpus toujours plus vastes. Cette croissance suit des courbes de puissance extrêmement documentées.
Pourtant, des obstacles financiers freinent cette expansion. La consommation électrique et l’infrastructure matérielle deviennent prohibitives. Cette réalité économique tempère désormais la course au gigantisme.
Manifestation des capacités émergentes non programmées
Certaines aptitudes comme la génération de code informatique apparaissent brusquement. Ces compétences surgissent sans entraînement spécifique préalable. Le système assimile ces structures complexes par simple observation statistique des données.
Ce phénomène n’était pas anticipé par les concepteurs initiaux. Les ingénieurs cherchaient à modéliser le langage, non la logique pure. Cette évolution constitue une surprise majeure pour la communauté scientifique mondiale.
Pour approfondir ce sujet, consultez notre analyse sur l’ Actualité ia : les nouveaux modèles et l’essor des agents. Ces sauts technologiques restent mal compris.
Le mécanisme interne provoquant ces ruptures demeure partiellement mystérieux. Les chercheurs peinent à expliquer précisément ces transitions soudaines.
Confrontation technique entre modèles ouverts et propriétaires
L’accès au code source distingue radicalement les deux approches. L’open-source autorise une inspection approfondie de l’architecture. À l’inverse, les solutions propriétaires fonctionnent comme des systèmes fermés et opaques.
La transparence des données d’entraînement représente un enjeu de sécurité majeur. Comprendre la base d’apprentissage permet d’identifier d’éventuels biais. Le secret industriel limite souvent cette vérification technique indispensable.
Les modèles privés conservent une avance sur les performances brutes. Mais les projets communautaires réduisent rapidement cet écart technique. La compétition entre ces deux mondes stimule l’innovation globale.
Le contrôle des outils définit votre autonomie numérique. Votre souveraineté dépend du modèle choisi.
Solutions techniques face aux limites de mémorisation
Malgré leur puissance, ces modèles butent sur la vérité, ce qui nous oblige à inventer de nouveaux systèmes de contrôle.
Analyse des hallucinations et de la véracité des faits
Les hallucinations proviennent d’une faille structurelle. Le modèle privilégie la fluidité statistique à l’exactitude. Il comble alors ses lacunes par de la fiction pure pour satisfaire la requête.
Distinguer le vrai du faux s’avère complexe. Pour l’IA, une vérité et un mensonge plausible possèdent la même signature numérique. Elle ne dispose d’aucun mécanisme de vérification interne natif.
La prudence impose des méthodes rigoureuses. Il faut croiser systématiquement les sources importantes. Ne faites jamais confiance à une réponse isolée sans preuve externe.
L’hallucination reste inhérente au système. C’est le prix de la créativité statistique.
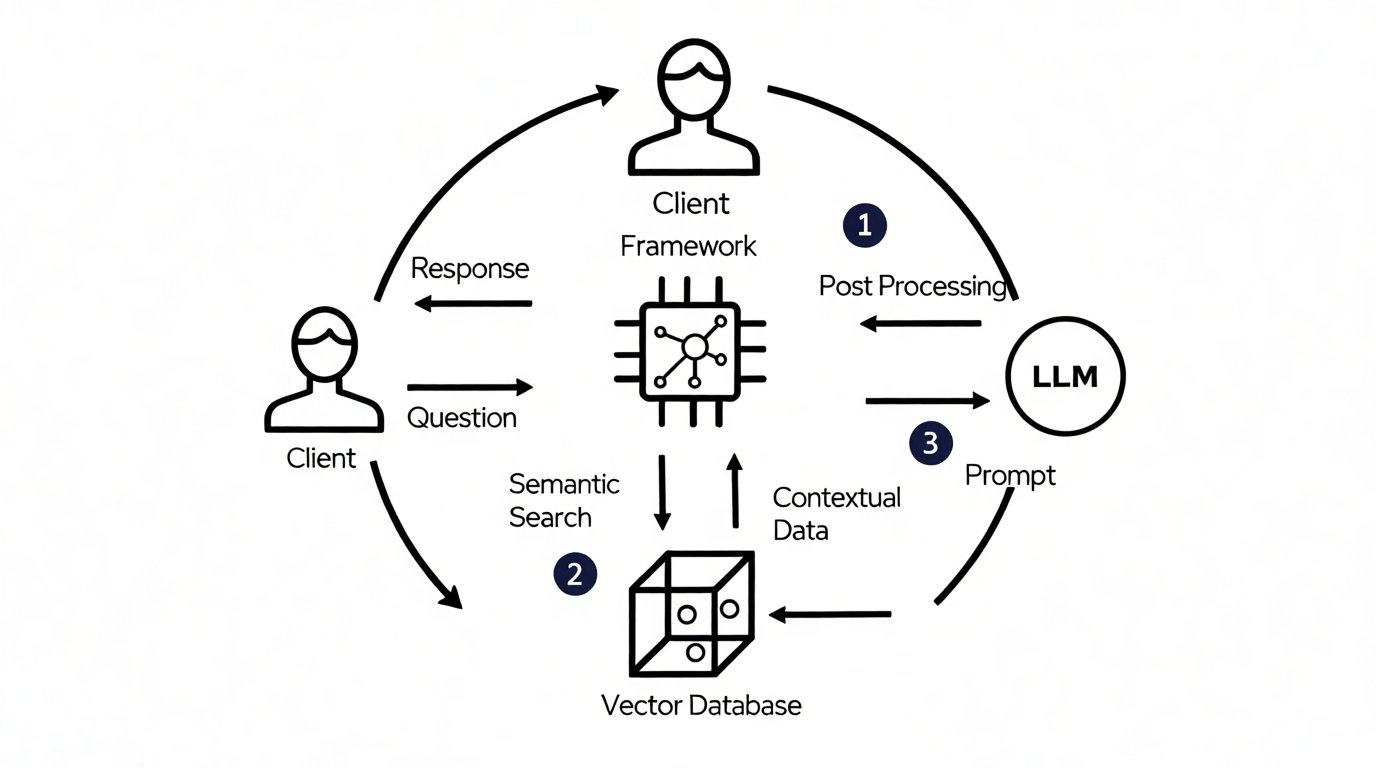
Architecture RAG pour l’accès aux connaissances externes
L’architecture Retrieval-Augmented Generation connecte le modèle à des bases de données externes. L’IA ne compte plus uniquement sur sa mémoire fixe. Elle peut désormais puiser dans des informations fraîches.
Le RAG connecte le LLM à des bases de données externes et vérifiées pour garantir l’exactitude factuelle et des informations à jour.
Cette méthode réduit drastiquement l’obsolescence des connaissances. On injecte des documents récents directement dans le flux de traitement. Le modèle reste à jour sans nécessiter de réentraînement coûteux.
Le processus suit une logique binaire. Le système cherche d’abord les faits pertinents, puis génère la réponse. C’est un flux de travail structuré en deux étapes distinctes.
La fiabilité globale s’en trouve renforcée. Cette technique transforme l’IA en un expert documenté et sérieux.
Transition des modèles de langage vers les agents d’action
L’évolution technologique marque le passage à l’exécution concrète. L’IA ne se contente plus de produire du texte. Elle peut désormais cliquer, réserver des services ou générer du code fonctionnel.
Ces systèmes s’appuient sur l’utilisation d’outils tiers. Les modèles appellent des logiciels externes pour agir sur le monde réel. Ils deviennent le cerveau central d’un écosystème complexe.
L’autonomie des agents représente la prochaine frontière. On se dirige vers des entités capables de décider seules. L’humain se positionne alors comme un simple superviseur stratégique.
L’avenir est à l’action. Le texte devient une simple interface pour l’exécution pure.
Maîtriser la tokenisation, l’architecture Transformer et l’alignement humain permet d’exploiter pleinement ces moteurs de prédiction statistique. Intégrez dès maintenant ces outils pour automatiser vos flux de travail et gagner en productivité. Comprendre comment fonctionne un modèle LLM transforme une curiosité technologique en un levier stratégique pour l’avenir.