


Concevoir un modèle performant sans maîtriser comment entraîner une intelligence artificielle expose les développeurs à des résultats imprécis ou des biais discriminatoires persistants. Ce processus technique repose sur une sélection rigoureuse de données qualifiées et le choix de paradigmes adaptés, comme l’apprentissage supervisé ou le deep learning, pour transformer une architecture brute en un système décisionnel fiable. En optimisant les hyperparamètres et en intégrant une supervision humaine stratégique, vous garantissez la robustesse opérationnelle de vos algorithmes face aux évolutions constantes des flux d’informations réels.
- Entraîner une intelligence artificielle : les trois paradigmes fondamentaux
- Qualité des données et préparation du pipeline d’entraînement
- Architecture technique et sélection de l’algorithme adapté
- Optimisation des performances et gestion des ressources matérielles
- Évaluation rigoureuse et suivi opérationnel du modèle
Entraîner une intelligence artificielle : les trois paradigmes fondamentaux
Après avoir posé le décor de l’IA moderne, il est temps de s’attaquer au cœur du sujet : la manière dont ces machines apprennent réellement.
Distinction entre apprentissage supervisé, non supervisé et par renforcement
L’apprentissage supervisé repose sur des données étiquetées fournies par un humain. À l’inverse, le mode non supervisé explore des structures de manière autonome. Cette approche permet de classer des informations sans intervention préalable.
Le renforcement fonctionne par un système de récompenses et de punitions. L’agent apprend ainsi par essais successifs pour maximiser ses gains. On utilise cette méthode principalement dans la robotique ou les jeux complexes.
Le tri d’emails illustre parfaitement le modèle supervisé classique. La recommandation de films exploite souvent le non supervisé. Ces situations simples démontrent comment entraîner une intelligence artificielle au quotidien.
| Paradigme | Mécanisme | Application |
|---|---|---|
| Supervisé | Données étiquetées | Détection de spam |
| Non supervisé | Patterns autonomes | Segmentation client |
| Renforcement | Récompense/Erreur | Robotique, Jeux |
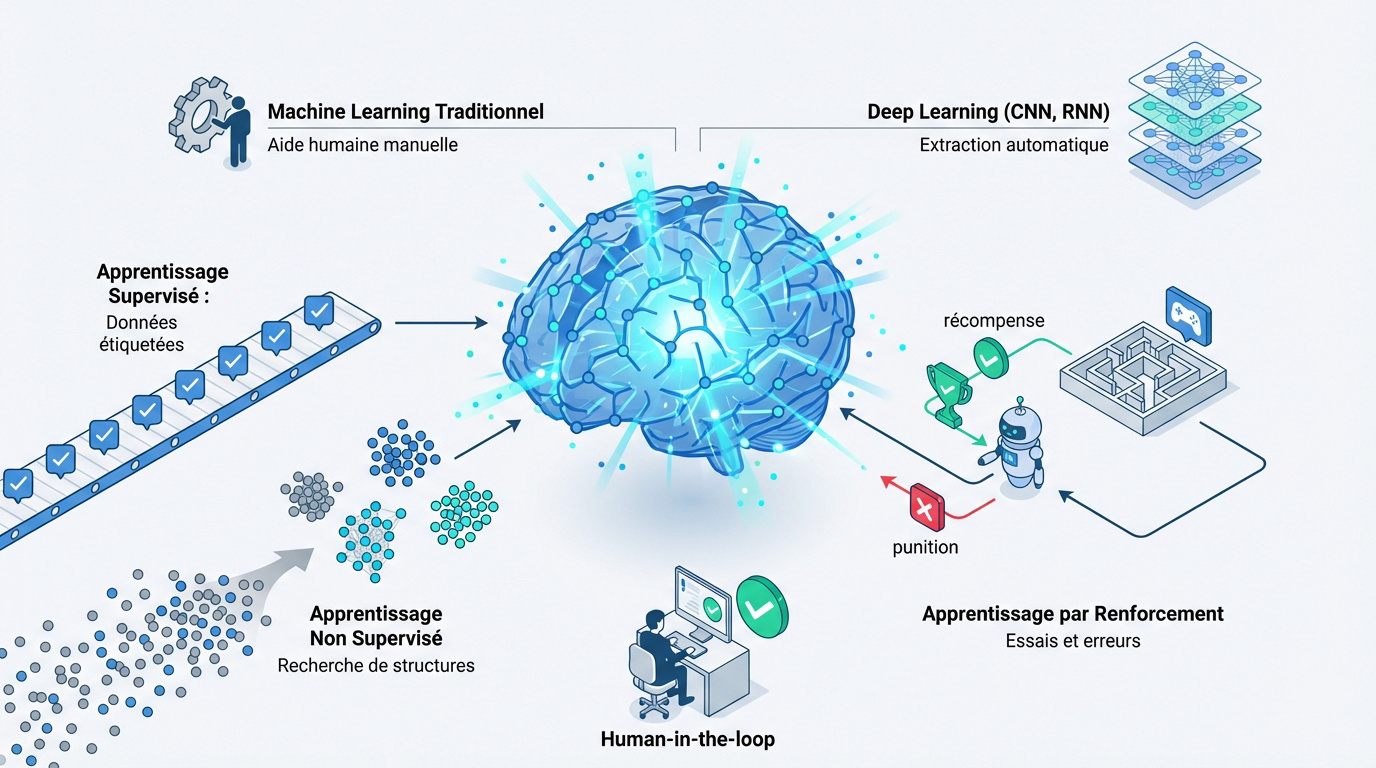
Comparaison entre Machine Learning traditionnel et Deep Learning
Le Machine Learning s’appuie sur des algorithmes statistiques classiques. Le Deep Learning utilise des réseaux de neurones profonds. Le choix dépend de la complexité des données à traiter.
L’extraction de caractéristiques nécessite une aide humaine en Machine Learning. Le Deep Learning automatise totalement cette étape cruciale. Les couches de neurones identifient seules les motifs pertinents.
Le Deep Learning exige des volumes de données massifs. En revanche, le modèle traditionnel reste performant sur de petits jeux structurés. Les ressources de calcul varient aussi selon l’approche choisie.
Idéal pour données structurées, nécessite une ingénierie manuelle et moins de puissance de calcul.
Adapté aux données brutes (images, texte), automatique mais très gourmand en données et GPU.
Place de l’intervention humaine dans le processus d’apprentissage
Le concept de Human-in-the-loop implique une validation humaine constante. L’expert intervient lorsque le système hésite sur une décision. Cette boucle sécurise la fiabilité des nouveaux modèles et agents IA déployés.
L’expertise métier permet d’affiner les résultats produits par l’algorithme. L’humain apporte un contexte spécifique que la machine ne perçoit pas. Cela accélère la convergence du modèle vers une précision optimale.
La supervision garantit que l’humain reste le garde-fou final. Le discernement reste indispensable pour valider les sorties. La machine complète l’intelligence humaine sans la remplacer totalement.
Qualité des données et préparation du pipeline d’entraînement
Mais avant de lancer les calculs, le véritable travail de fond commence par la matière première : la donnée brute.
Méthodes de collecte et de nettoyage des jeux de données
Le nettoyage impose de supprimer les doublons pour ne pas fausser l’apprentissage. Gérer les valeurs manquantes devient alors vital. Un jeu de données propre évite ainsi des erreurs futures majeures.
L’uniformisation des formats reste une étape indispensable du processus technique. Tous les fichiers doivent impérativement se ressembler. Cette cohérence garantit un traitement fluide par l’algorithme de machine learning choisi.
La segmentation des ensembles constitue la phase finale de préparation. Il faut séparer strictement l’entraînement, la validation et le test. C’est la règle d’or pour évaluer l’IA honnêtement et sans biais.
- Collecte : Rassemblement de données variées et pertinentes.
- Nettoyage : Suppression des doublons et gestion des valeurs manquantes.
- Uniformisation : Mise en conformité des formats et des unités.
- Segmentation : Division en lots d’entraînement, de validation et de test.
Importance de l’étiquetage et de la représentativité statistique
L’annotation est un processus rigoureux où chaque donnée reçoit une étiquette précise. Pour l’apprentissage supervisé, ce travail long est indispensable. Découvrez d’ailleurs comment utiliser l’intelligence artificielle avec des jeux de données qualifiés.
Un échantillonnage déséquilibré présente des risques techniques réels pour le modèle. Si une catégorie manque, l’IA sera aveugle lors de son déploiement. La représentativité statistique assure que le modèle comprend la réalité globale de son environnement.

Le volume de données détermine souvent la précision finale du système. Plus la tâche est complexe, plus il faut de données. La fiabilité des prédictions en dépend directement pour l’utilisateur final.
Identification et correction des biais pour une IA éthique
Repérer les biais cognitifs ou historiques est un impératif pour les développeurs. Les données reflètent souvent nos propres préjugés humains. Il faut donc les identifier avant qu’ils ne s’installent durablement.
Des stratégies de rééquilibrage permettent d’ajuster les poids des variables sensibles. On peut aussi ajouter des données synthétiques pour combler les manques. L’objectif est d’assurer l’équité des prédictions futures du modèle.
La responsabilité du concepteur est engagée lors de chaque étape technique. La neutralité n’est jamais automatique dans un algorithme. C’est un choix conscient effectué lors de la préparation du pipeline d’entraînement.
Architecture technique et sélection de l’algorithme adapté
Une fois les données prêtes, il faut choisir le moteur qui va les transformer en intelligence : l’algorithme.
Critères de choix entre réseaux de neurones et modèles statistiques
Les arbres de décision offrent une grande clarté pour des données structurées. À l’opposé, les réseaux de neurones excellent dans la capture de motifs complexes. Les CNN dominent l’analyse d’images. Les RNN traitent avec précision les séries temporelles.
L’adéquation dépend directement de la nature de vos données. Le texte et les séquences exigent des approches spécifiques. Chaque type de signal possède son modèle idéal. Une analyse préalable évite des erreurs coûteuses lors de l’entraînement.
CNN pour les images, RNN pour les données séquentielles, GPT pour le langage naturel et Arbres de décision pour la modélisation statistique.
La puissance de calcul disponible reste un facteur déterminant. Un modèle très complexe exige des ressources matérielles massives. Il faut rester pragmatique face aux capacités de vos serveurs. L’efficience énergétique devient aussi un critère de sélection.
Exploitation des modèles open-source et des bibliothèques standards
Identifier les avantages du pré-entraîné est une étape stratégique. Réutiliser des architectures reconnues fait gagner un temps précieux. C’est désormais la base du développement moderne en intelligence artificielle. Pourquoi repartir de zéro ?
Des plateformes spécialisées proposent des milliers de modèles gratuits. Cela démocratise l’accès à des technologies de pointe pour tous. Vous pouvez d’ailleurs consulter les meilleurs outils IA 2026 pour identifier les solutions émergentes les plus performantes.
La communauté joue un rôle de garde-fou indispensable. L’open-source sécurise les algorithmes par une relecture collective constante. Les améliorations sont partagées instantanément par les chercheurs. Cette transparence renforce la fiabilité globale des systèmes produits.
Panorama des frameworks de développement actuels
TensorFlow, PyTorch et Scikit-learn dominent largement le marché actuel. Chaque outil possède une philosophie et une structure propre. Le choix final dépend souvent de l’aisance du développeur avec le code Python. La flexibilité varie selon l’outil.
Certains environnements sont optimisés pour la recherche fondamentale. D’autres facilitent grandement la mise en production à l’échelle industrielle. Il est crucial d’analyser la capacité de déploiement sur différents supports. La compatibilité cloud est un atout majeur.
Pour comment entraîner une intelligence artificielle efficacement, privilégiez la documentation. Un framework vivant dispose d’un support communautaire actif et réactif. Vérifiez la fréquence des mises à jour avant de vous engager. La pérennité de votre projet en dépend.
Optimisation des performances et gestion des ressources matérielles
Choisir le bon outil ne suffit pas, il faut maintenant régler les curseurs pour obtenir une précision maximale.
Ajustement des hyperparamètres pour éviter le surapprentissage
Le taux d’apprentissage et la taille des lots définissent la vélocité de la convergence. Ces variables de configuration externes influencent directement la vitesse d’entraînement. Un paramétrage erroné peut freiner ou bloquer totalement la progression du modèle.
Les techniques de régularisation, comme le Dropout, limitent la complexité du réseau. Elles empêchent l’overfitting, phénomène où l’IA mémorise les données au lieu de les comprendre. L’objectif final reste une capacité de généralisation optimale.
L’optimisation itérative ajuste les poids pour réduire la fonction de perte. Ce processus minutieux affine les prédictions à chaque époque. C’est une quête de précision technique constante.
Transfer Learning : Réutilisation d’un modèle pré-entraîné sur une nouvelle tâche liée pour économiser du temps et des ressources de calcul.
Fine-tuning : Ajustement léger des paramètres d’un modèle pré-entraîné pour le spécialiser dans un domaine précis.
Avantages du Transfer Learning pour les projets à ressources limitées
Le Fine-tuning adapte un modèle déjà expert à une mission spécifique. On exploite des connaissances préexistantes pour répondre à un besoin nouveau. C’est comme donner une spécialité technique à un savant.
Cette méthode garantit un gain de temps et d’énergie considérable. Créer un modèle à partir de zéro exige une puissance de calcul onéreuse. Le transfert permet d’obtenir des résultats professionnels avec une automatisation IA efficace.
L’adaptation se concentre souvent sur la couche de sortie. On modifie la terminaison du réseau pour l’orienter. Le socle de savoir initial est ainsi préservé.
Rôle des GPU et TPU dans l’accélération des calculs
Les processeurs graphiques sont devenus le standard pour comment entraîner une intelligence artificielle. Les GPU traitent des milliers d’opérations simultanément. Cette architecture parallèle est vitale pour les réseaux de neurones profonds.
Les Tensor Processing Units (TPU) offrent des performances supérieures. Ces puces spécialisées sont conçues exclusivement pour les charges de travail liées à l’IA. Elles surpassent les capacités des processeurs centraux classiques.
Le recours aux infrastructures cloud simplifie l’accès à ces technologies. Il n’est plus impératif d’investir dans un matériel physique coûteux. On mobilise la puissance nécessaire selon ses besoins réels.
Évaluation rigoureuse et suivi opérationnel du modèle
Le modèle tourne, mais est-il vraiment efficace ? C’est ici que la rigueur mathématique rencontre la réalité du terrain.
Indicateurs de précision et protocoles de validation
La précision mesure la justesse des prédictions positives. Le rappel identifie la capacité à détecter tous les cas réels. Le score F1 harmonise ces deux données pour un diagnostic complet.
Proportion globale de classifications correctes sur le total des tests effectués.
Fraction des cas positifs réels que le modèle a réussi à détecter.
Moyenne harmonique équilibrant précision et rappel pour les données déséquilibrées.
La validation croisée fragmente les données en plusieurs sous-ensembles distincts. Le modèle subit des tests répétés sur ces segments variés. Cette méthode garantit que la performance ne provient pas d’une anomalie statistique.
Les tests utilisateurs apportent une validation finale indispensable. La technique pure ne suffit pas à confirmer la pertinence métier. L’humain vérifie si l’outil répond concrètement aux besoins réels.
Gestion de la dérive des données après la mise en production
Surveiller la perte de performance temporelle est indispensable car les environnements évoluent. Une IA efficace peut décliner si les données d’entrée changent. Il est vital d’intégrer l’IA pour entreprises avec une vigilance constante sur sa fiabilité.
Des alertes de comportement signalent toute modification des habitudes de l’audience. Le système doit détecter ces variations statistiques immédiatement. La réactivité permet d’ajuster le tir avant que les erreurs ne deviennent coûteuses.
Anticiper les cycles de ré-entraînement assure la pérennité du dispositif technique. Les mises à jour régulières maintiennent le niveau de précision requis. C’est un processus itératif indispensable pour rester performant.
Accessibilité de l’entraînement via les solutions no-code et AutoML
L’entraînement sans programmation devient possible grâce aux interfaces visuelles simplifiées. Ces outils permettent de concevoir des modèles sans écrire de code. Ils démocratisent l’accès aux technologies avancées pour les non-spécialistes.
L’AutoML automatise la recherche du meilleur algorithme pour un problème donné. Le système teste plusieurs configurations pour optimiser les résultats seul. Les entreprises gagnent ainsi un temps précieux lors du déploiement initial.
Ces solutions présentent toutefois des limites en termes de personnalisation profonde. Elles conviennent parfaitement aux projets standards mais peuvent manquer de souplesse. Le choix dépend directement de l’ambition technique du projet.
Maîtriser l’art d’entraîner une intelligence artificielle repose sur une préparation rigoureuse des données, le choix d’algorithmes adaptés et une optimisation continue. En intégrant l’expertise humaine au cœur du pipeline technique, vous garantissez des performances fiables et éthiques. Agissez dès maintenant pour transformer vos données brutes en actifs stratégiques et pérennes.