


Comprendre comment fonctionne un modèle IA semble souvent relever de l’abstraction pure pour les utilisateurs confrontés à des résultats parfois imprévisibles. Cet article décompose la hiérarchie technique entre Machine Learning et Deep Learning pour révéler les mécanismes mathématiques qui transforment des données brutes en décisions automatisées. Vous découvrirez comment l’ajustement des poids synaptiques et la rétropropagation des erreurs permettent à ces réseaux de neurones d’affiner leur précision pour surpasser les capacités de traitement humaines.
- Architecture et fondements d’un modèle d’intelligence artificielle
- Fonctionnement de l’apprentissage à partir des données
- Ajustement des paramètres et mécanisme de rétropropagation
- Architecture des LLM et cycle de vie opérationnel
Architecture et fondements d’un modèle d’intelligence artificielle
Pour saisir comment fonctionne un modèle IA, il faut d’abord écarter les fantasmes de science-fiction et observer la hiérarchie technique qui structure cette discipline mathématique.
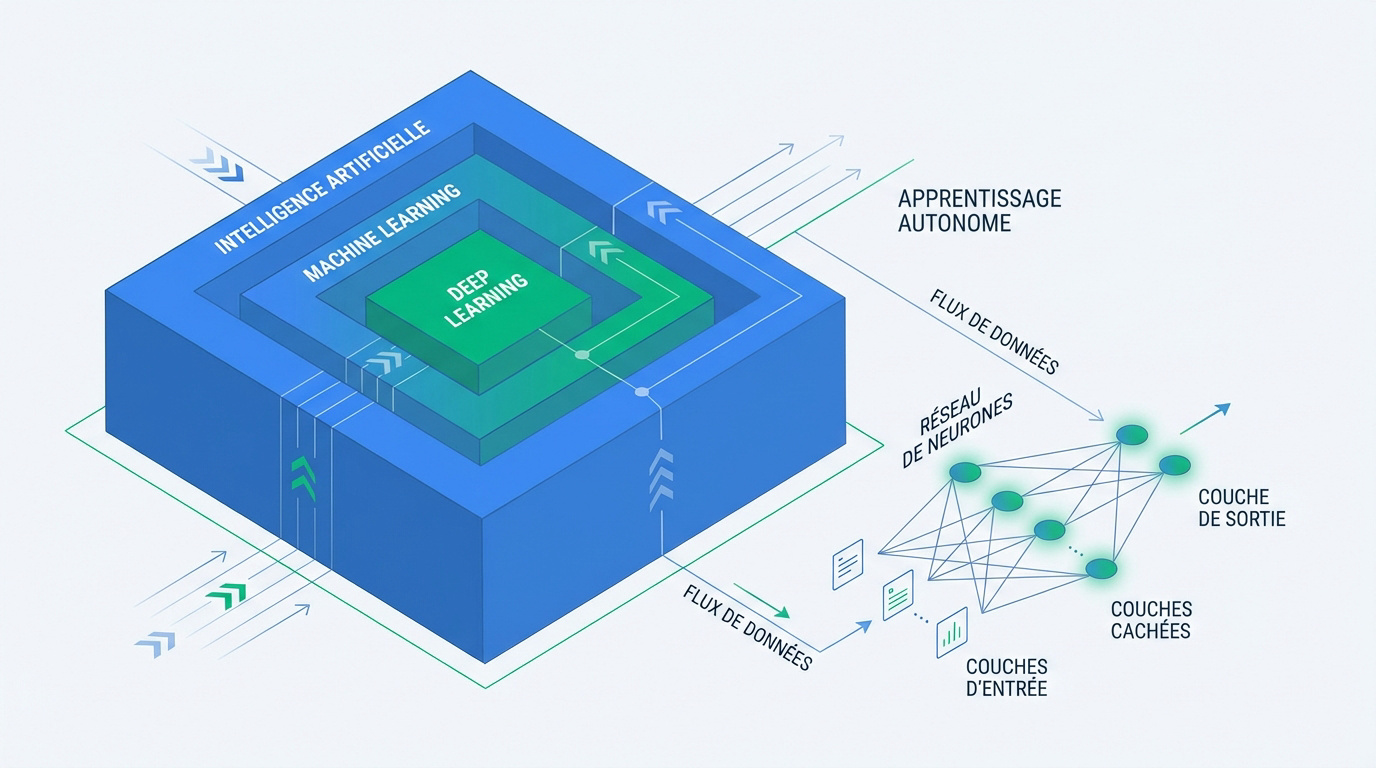
L’IA est le concept global de simulation de l’intelligence. Le Machine Learning en est la branche d’apprentissage statistique, tandis que le Deep Learning utilise des réseaux neuronaux complexes.
Distinction entre IA, Machine Learning et Deep Learning
L’intelligence artificielle représente l’objectif global de créer des machines intelligentes. Le Machine Learning constitue une branche spécifique dédiée à l’apprentissage. Le Deep Learning affine encore cette approche par l’analyse profonde.
Un modèle se définit comme un système purement mathématique. Il traite des données massives via des algorithmes complexes. Ce n’est pas de la magie, mais du calcul pur et dur.
Chaque niveau imbriqué apporte une autonomie croissante au système. La machine apprend seule, sans nécessiter une programmation explicite pour chaque scénario rencontré.
Rôle des réseaux de neurones et organisation en couches
La structure s’organise en différentes couches successives. On distingue la couche d’entrée, les couches cachées et la sortie finale. Chaque nœud imite grossièrement un neurone biologique interconnecté.
L’information circule de manière unidirectionnelle au sein de l’architecture. Les données passent systématiquement d’une strate à l’autre. Le réseau transforme ainsi le signal de façon progressive.
Plus le nombre de couches est important, plus l’analyse devient fine. Cette profondeur architecturale est le cœur même du concept de Deep Learning pour traiter des données brutes.
Fonctionnement de l’apprentissage à partir des données
Maintenant que la structure est claire, voyons comment cette carcasse mathématique prend vie grâce aux données.
Méthodes supervisées, non supervisées et par renforcement
L’apprentissage supervisé utilise des données étiquetées pour guider la machine. À l’inverse, le mode non supervisé travaille sur des informations brutes. L’algorithme doit alors identifier seul des motifs ou des structures. C’est avant tout une question de structure de départ.
Le renforcement introduit un système de récompense pour orienter les actions. L’IA teste des décisions au sein d’un environnement. Elle reçoit des points positifs ou négatifs. Elle optimise ainsi son score final par itérations successives.
Ces mécanismes permettent de comprendre comment utiliser l’intelligence artificielle au quotidien. Ces méthodes définissent la logique de traitement des outils actuels.
Le supervisé prédit via des étiquettes. Le non supervisé découvre des relations sans aide humaine.
L’IA maximise ses gains en corrigeant ses erreurs après chaque action testée.
Importance de la préparation et du nettoyage des données
La qualité prime systématiquement sur la quantité des informations. Des données sales produisent inévitablement des résultats biaisés. Le nettoyage constitue donc une étape vitale pour la fiabilité du modèle.
La catégorisation intervient avant l’injection des données. Il faut trier et normaliser chaque flux d’information. Sans cela, l’algorithme s’embrouille inutilement. La précision dépend directement de ce travail préparatoire.
Ce processus est au cœur de l’intelligence artificielle entreprise : outils et enjeux. Une donnée bien préparée garantit des décisions stratégiques sûres.
Ajustement des paramètres et mécanisme de rétropropagation
Le modèle a ses données, mais il doit encore apprendre de ses erreurs pour devenir performant.
Analogie des poids et réglage de la balance de précision
Le fonctionnement interne d’un algorithme ressemble à une balance de précision. On ajuste les petits poids pour trouver l’équilibre. C’est exactement ce que fait l’algorithme en interne.
Chaque connexion a une importance variable. Certaines informations comptent plus que d’autres. Le modèle identifie ces priorités durant l’entraînement pour affiner ses prédictions futures.
Ces réglages définissent la capacité du système. Vous pouvez consulter cette actualité ia : les nouveaux modèles et l’essor des agents avec une ancre naturelle. L’apprentissage modifie ainsi chaque paramètre structurel.
Processus de rétropropagation et fonctions d’activation
La rétropropagation est un retour en arrière. Le modèle voit l’erreur finale et remonte la chaîne pour corriger les poids. C’est une méthode d’essai-erreur mathématique indispensable.
Les fonctions d’activation décident si un neurone doit envoyer un signal. C’est le déclencheur logique entre deux couches successives. Elles permettent de modéliser des relations complexes et non linéaires.
Cette architecture explique comment fonctionne un modèle IA. Elle favorise l’automatisation par intelligence artificielle et son essor avec une ancre naturelle. La boucle de rétroaction garantit la fiabilité du système.
Architecture des LLM et cycle de vie opérationnel
Ces principes généraux s’appliquent de façon spectaculaire aux outils que nous utilisons tous les jours, comme les LLM.
Spécificités techniques des grands modèles de langage
L’architecture Transformer constitue le socle de ces systèmes. Ce mécanisme traite les données textuelles de manière globale et simultanée. Il parvient ainsi à saisir les relations entre des mots pourtant éloignés.
Il convient de distinguer les modèles généralistes des versions spécialisées. Les premiers affichent une polyvalence étendue sur divers sujets. À l’inverse, les seconds sont optimisés pour exceller dans un domaine technique précis.
Cette structure permet de comprendre comment fonctionne un modèle IA au quotidien. Pour explorer ces capacités, découvrez les meilleurs outils ia 2026 pour votre productivité. Ces solutions exploitent pleinement la puissance des réseaux neuronaux profonds.
Transition entre phase d’entraînement et inférence
Le cycle de vie sépare strictement l’entraînement de l’inférence. L’entraînement initial s’avère extrêmement lourd et coûteux en ressources. L’inférence désigne l’utilisation concrète du modèle une fois celui-ci figé. C’est durant cette phase que la réponse est générée pour l’utilisateur.
Phase lourde et coûteuse. Construction du modèle à partir de vastes jeux de données.
Usage quotidien. Modèle figé produisant des résultats en temps réel pour l’utilisateur.
La mise à jour des connaissances pose un défi majeur. Un modèle classique n’apprend plus aucune information après sa sortie officielle. Des méthodes comme le RAG permettent alors d’actualiser son savoir sans réentraînement.
Cette réactivité dépend directement de la puissance de calcul disponible. Les processeurs graphiques GPU restent indispensables pour supporter ces opérations logiques massives.
Comprendre le fonctionnement d’un modèle d’IA repose sur l’articulation entre l’architecture des réseaux de neurones, la qualité des données d’entraînement et l’ajustement mathématique par rétropropagation. Maîtriser ces rouages techniques devient indispensable pour piloter efficacement l’automatisation et rester compétitif dans un paysage technologique en mutation rapide. La précision de vos futurs systèmes dépend dès aujourd’hui de la rigueur de cette ingénierie.